프로젝트] : 타이타닉 데이터셋 분석
[목표] : 타이타닉 데이터셋을 분석하여, 생존/죽음과 상관관계가 있는 지표들을 찾기
- 다양한 시행착오들을 기록할 예정입니다.
1. Kaggle 에서 제공하는 Titanic Data 다운로드 받기
https://www.kaggle.com/c/titanic/data

Titanic: Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
2. 필요한 모듈, 데이터셋 import , isnull().sum() 을 이용하여 결측값 갯수 확인.

3. [Age] 열의 결측값 177개 확인.
- 결측값 처리할 방법을 고민하다가 평균값으로 채우는 것 외의 조금더 의미있는 분석을 통해서 채우고자 함
- "나이(Age)"와 "요금(Fare)" 사이의 상관관계가 있을 것이라고 생각. -> 보통 티켓은 학생/어른/우대로 구분이 되어 있기 때문에.
- 결측값이 없는 Fare 와 Age 의 데이터만 따로분류하고, 그 데이터를 선형회귀분석을 하여 나이를 예측하기로 함.
[과정] - 선형회귀분석을 통한 Age값 예측하기


- 우선 결측값에 fillna 를 이용해 NaN 값에 0을 채운다. (Masking으로 편하게 나누기 위해서)
- masking을 이용하여, Age 값이 0 인것과 0이 아닌것을 나누어 2개의 데이터프레임을 만든다.
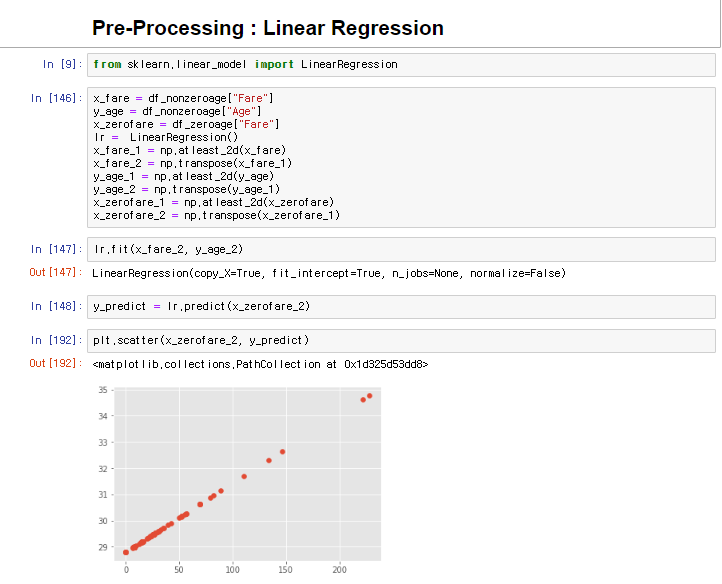
- Python의 sklearn 모듈을 사용하여 선형회귀를 사용하여 결측값을 예측하고자 함.
- Linear Regression을 사용하기 위해서는 우선 x axis 와 y axis에 들어가는 값을 numpy array 로 바꾸어주어야한다.
( 이 과정이 다소 귀찮다. 더 편한 방법을 찾아보고 알게되면 추후에 포스팅 할 예정)
- 결측값이 없는 Fare 와 Age 로 선형회귀분석을 하고, 결측값을 갖는 Age를 Fare를 이용해 예측하였다.
4. 선형회귀분석으로 예측한 나이값(Age)을 요금(Fare)과 같이 볼 수 있도록 데이터프레임으로 합치기

- 크게 의미는 없는 과정이지만, Fare와 예측된 Age를 보면서 타당한 예측이 되었는지를 한눈에 보고싶었다.
- 다소 간단할 줄 알았지만, numpy -> DataFrame으로 오기위해선 1차원 Data 이어야 되므로 변환을 해줘야한다.
(이 과정에서 np.squeeze 를 이용하였고 , 1차원으로 만들때 굉장히 유용하다.)
- 추가로, numpy 배열의 차원을 확인하기 위해서는 .shape을 이용하면 된다.

- 2개의 DataFramedme을 합칠 때는 pd.concat 을 이용하면 된다.
5. 결과 및 분석
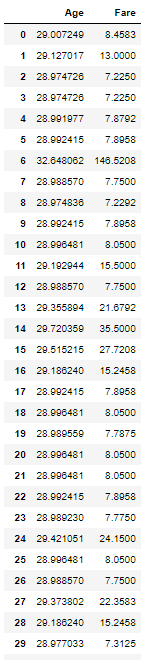
- 내가 얻어낸 Fare로 예측한 Age 값 이다. 타당한 값이 나오는지 확인을 위해 구한 DataFrame을 확인해보았다.
- 총 177개의 값이 있지만 공간 상 29개만 첨부하였다.
- 다소 충격적인 결과가 나왔다.
: 8.45 달러 지불 -> 29 살 / 13달러 지불 -> 29.12 살
: 의미가 없는 결과이다. 0.12살이 많은 것은 중요하지 않다.
- 선형회귀분석에서의 "기울기" 의 설정이 필요하다고 판단하였다. 다음 포스팅에서는 직접 함수를 정의하거나, 기울기를 조정하여 의미있는 예측값이 나오도록 해보겠다.
'Python > Projects' 카테고리의 다른 글
| [파이썬][데이터분석] - 카카오톡 대화를 워드클라우드(WordCloud)로 [1]! (0) | 2019.08.23 |
|---|
